Projects
Selected agent systems and research engineering work.
Project Index
From research prototypes to deployable agent systems
The first section highlights the three projects I want to foreground right now. The second section shows the research and infrastructure work around them.
Selected Projects
Recent work in focus

codex-long-running-harness
Codex-first harness for long-running app development with sprint planning, evaluator loops, and benchmark snapshots.
- Breaks open-ended app development into inspectable sprints.
- Couples planner, generator, and evaluator roles instead of single-shot prompting.
- Saves benchmark snapshots so progress is measurable and reproducible.

TaskCaptain
Supervised execution platform for real workspaces, with transparent agent runs, task state, and local-first control.
- Runs agents inside real project workspaces with visible task state.
- Keeps logs, artifacts, and configuration boundaries explicit.
- Positions AI as a supervised executor rather than a chat-only assistant.

crewai-rs
Rust-native multi-agent orchestration with typed tasks, deterministic flow control, and deployment-friendly runtime design.
- Rebuilds multi-agent orchestration in Rust rather than Python glue code.
- Uses typed runtime concepts for agents, tasks, crews, and flows.
- Targets lower overhead and more deployable agent infrastructure.
Research Engineering Archive
Earlier systems, algorithms, and performance work

OverSearchGuard
Conflict-aware evidence thinning for agentic RAG, with cost-aware robustness to duplicated noise.
- Caps repeated low-quality evidence before generation.
- Models reliability and recency without fine-tuning.
- Improves accuracy while sharply cutting token usage.
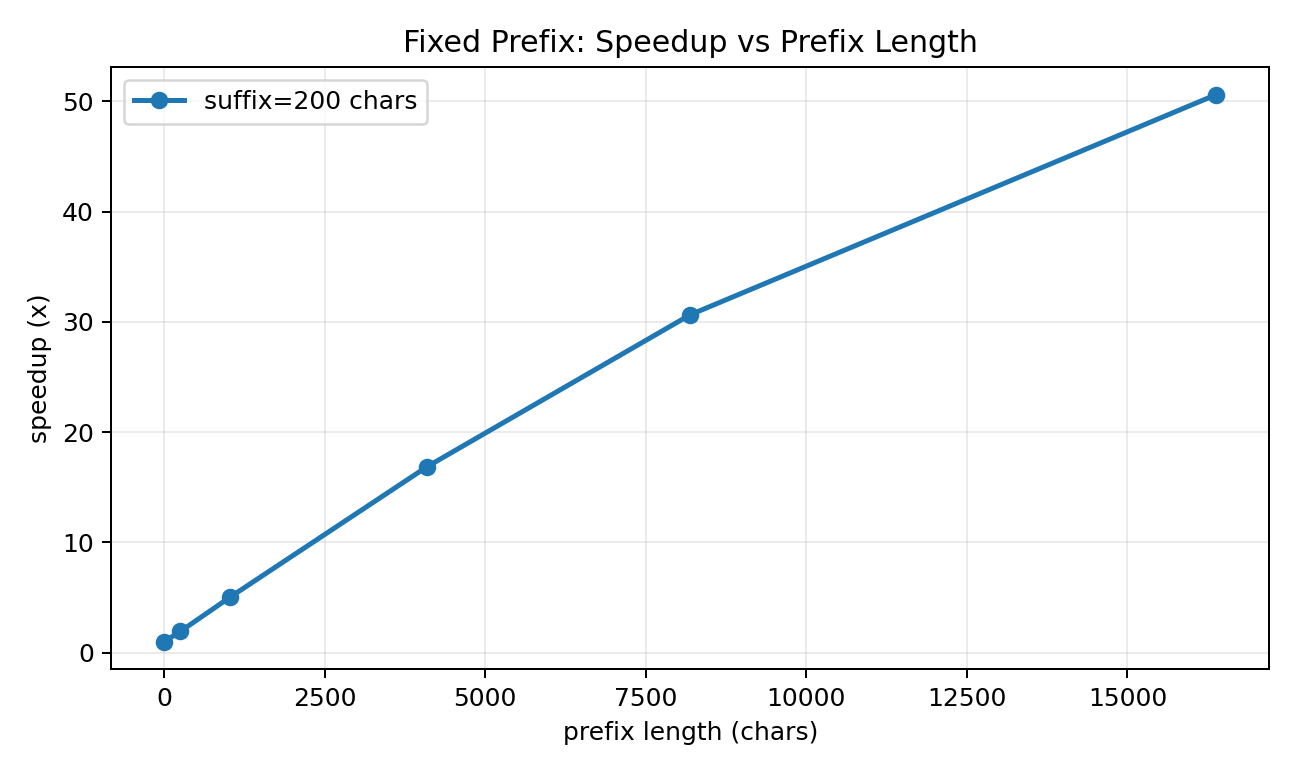
FlashToken
Tokenizer-side prefix caching for low-latency LLM systems, with 27x-37x speedups on reusable prompts.
- Reuses long prompt prefixes without touching model weights.
- Supports both fixed-prefix and append-only chat workflows.
- Delivers large speedups while preserving exact token equivalence.

OrderGuard
Permutation-marginalized LLM judging, reranking, and tool selection that reduces order sensitivity at inference time.
- Treats candidate order as a nuisance variable at inference time.
- Uses low-variance permutation schedules plus adaptive stopping.
- Improves macro accuracy on Qwen3 evaluation suites.
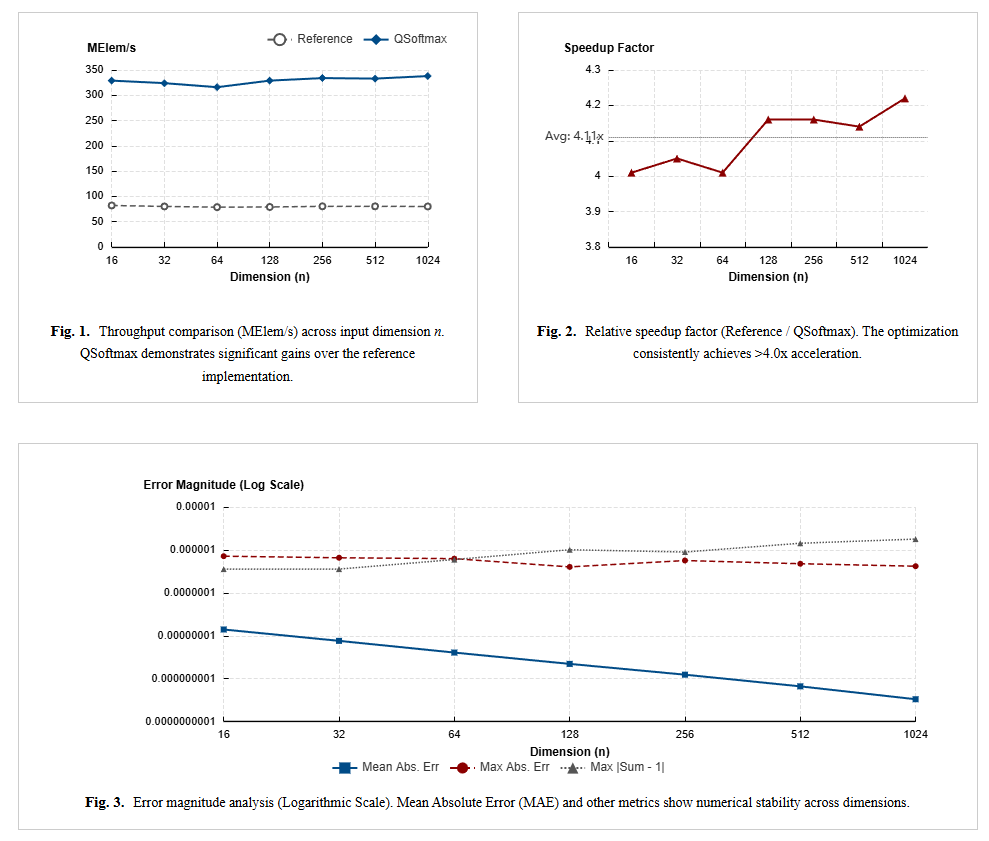
Turbo-Softmax
Fast high-precision Softmax kernels in C for resource-constrained CPUs and MCUs.
- Targets generic MCUs with IEEE-754-aware implementation tricks.
- Balances numerical precision and throughput.
- Shows early low-level systems interest before the newer agent stack.