AI Systems Researcher
I build long-running agent systems that stay inspectable, reproducible, and fast.
My work sits between research and systems engineering: long-horizon coding harnesses, supervised execution platforms, Rust-native multi-agent orchestration, and reliability tooling for LLM inference and RAG.

Current focus
- Long-running coding agents with explicit planning and evaluator loops
- Local-first supervised execution platforms for real workspaces
- Rust-native orchestration for typed multi-agent workflows
Research Focus
What I am optimizing for
Long-running agent systems
Designing harnesses where planning, generation, evaluation, and checkpointing are first-class runtime concepts rather than prompt hacks.
Reliable execution infrastructure
Building agent software that can work inside real project directories, leave auditable traces, and remain useful under human supervision.
Inference and RAG efficiency
Working on tokenization, kernels, reranking robustness, and evidence governance so LLM systems are faster and less fragile.
Selected Projects
Three recent projects I want to foreground
They cover long-horizon development harnesses, supervised execution, and Rust-native multi-agent orchestration.

codex-long-running-harness
Codex-first harness for long-running app development with sprint planning, evaluator loops, and benchmark snapshots.
- Breaks open-ended app development into inspectable sprints.
- Couples planner, generator, and evaluator roles instead of single-shot prompting.
- Saves benchmark snapshots so progress is measurable and reproducible.

TaskCaptain
Supervised execution platform for real workspaces, with transparent agent runs, task state, and local-first control.
- Runs agents inside real project workspaces with visible task state.
- Keeps logs, artifacts, and configuration boundaries explicit.
- Positions AI as a supervised executor rather than a chat-only assistant.

crewai-rs
Rust-native multi-agent orchestration with typed tasks, deterministic flow control, and deployment-friendly runtime design.
- Rebuilds multi-agent orchestration in Rust rather than Python glue code.
- Uses typed runtime concepts for agents, tasks, crews, and flows.
- Targets lower overhead and more deployable agent infrastructure.
Research Engineering Archive
Earlier systems that still anchor the stack

OverSearchGuard
Conflict-aware evidence thinning for agentic RAG, with cost-aware robustness to duplicated noise.
- Caps repeated low-quality evidence before generation.
- Models reliability and recency without fine-tuning.
- Improves accuracy while sharply cutting token usage.
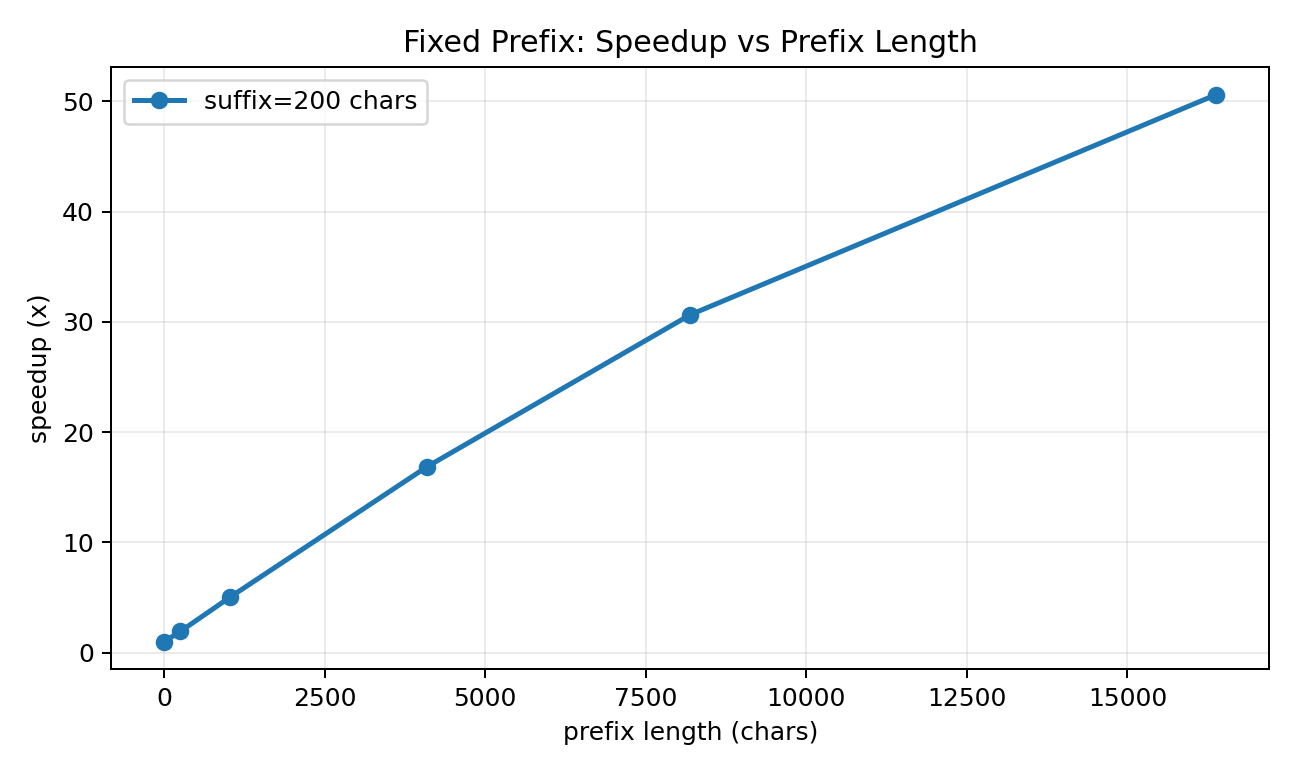
FlashToken
Tokenizer-side prefix caching for low-latency LLM systems, with 27x-37x speedups on reusable prompts.
- Reuses long prompt prefixes without touching model weights.
- Supports both fixed-prefix and append-only chat workflows.
- Delivers large speedups while preserving exact token equivalence.

OrderGuard
Permutation-marginalized LLM judging, reranking, and tool selection that reduces order sensitivity at inference time.
- Treats candidate order as a nuisance variable at inference time.
- Uses low-variance permutation schedules plus adaptive stopping.
- Improves macro accuracy on Qwen3 evaluation suites.
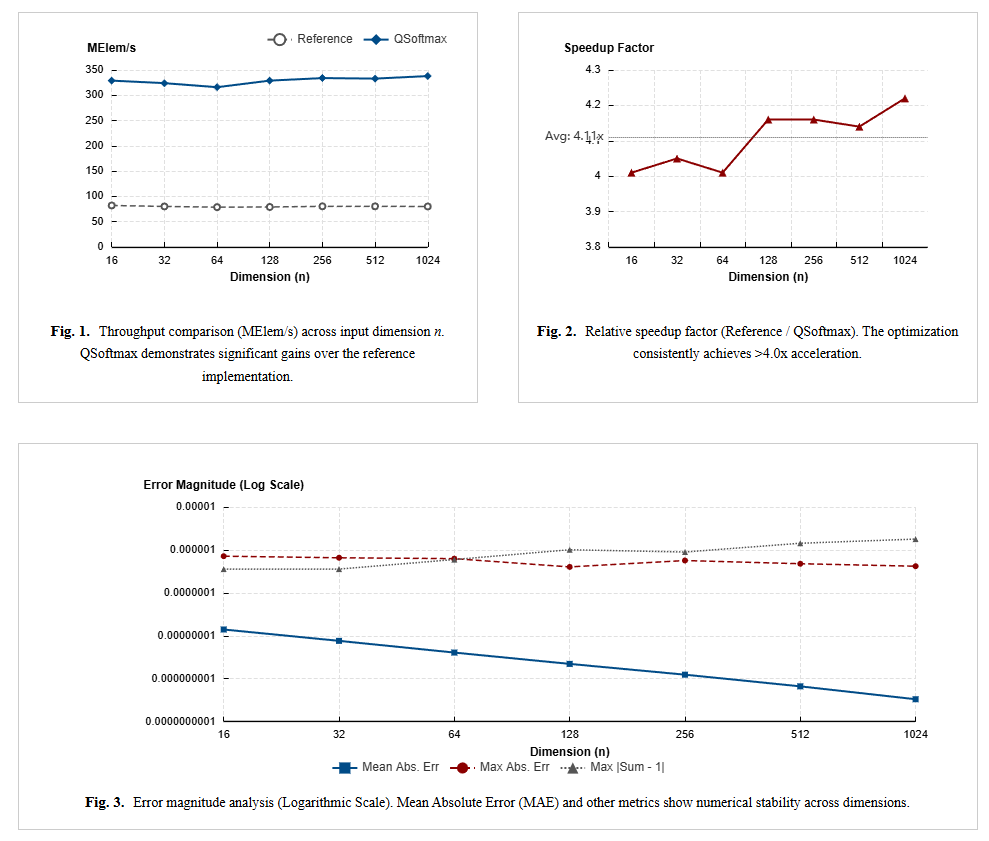
Turbo-Softmax
Fast high-precision Softmax kernels in C for resource-constrained CPUs and MCUs.
- Targets generic MCUs with IEEE-754-aware implementation tricks.
- Balances numerical precision and throughput.
- Shows early low-level systems interest before the newer agent stack.
Education
Academic path
University of Cambridge
Expected 2026–2027 · Visiting Student · CSC Full Scholarship
University of Electronic Science and Technology of China
2024–2027 · MPhil in Electronic Science and Technology · GPA 3.86/4.0 · Grade A+
University of Electronic Science and Technology of China
2020–2024 · BEng in Electronic Science and Technology · GPA 3.82/4.0 · Grade A+
Honors
Honors and research context
IEEEXtreme
Global Top 5% in the 24-hour programming competition, 2021.
Honors Degree
Top 2 in college, Outstanding Graduate.
Research orientation
Agent systems, evaluation infrastructure, inference optimization, and reliability-aware RAG.